调试不可见的东西:为什么事件系统需要自己的可观测层
QA 提了个 Bug:"玩家捡起钥匙后门没开。"
简单吧?大概是缺了个引用或者条件写错了。你打开工程,捡起钥匙,然后……门开了。在你机器上没问题。于是你问测试员复现步骤,他说"大约 30% 的概率出现,通常在存档/读档之后。"
现在你进入了调试地狱。在钥匙拾取事件、背包更新、任务进度检查、和门的解锁条件之间的链路某处,有东西间歇性地失败。但是哪一环?事件没触发?触发了但监听器没订阅?订阅了但条件评估为 false?条件是对的但门的状态在加载后是过期的?
你不知道。事件系统也不会告诉你。它是"发射后不管" —— 重点在"不管"。
这就是每个事件驱动的 Unity 项目迟早都会撞上的可观测性断层。它不只是调试的不便 —— 它是一个架构盲区,让重构变得危险、性能调优成为不可能、新成员上手变得痛苦。今天我想聊聊这个断层为什么存在、它到底让你付出了多少代价、以及一个靠谱的解决方案是什么样的。
"它触发了吗?"这个问题
事件系统里最基本的调试问题看似简单:事件触发了吗?
当 PlayerCombat 调用 onDamageDealt.Raise(42) 时,事件系统遍历监听器、调用它们的处理器、然后返回。没有日志。没有追踪。没有触发记录。信息在 Raise 完成的瞬间就蒸发了。
这跟直接方法调用有本质区别。如果 PlayerCombat.TakeDamage() 直接调用 HealthBar.UpdateDisplay(),你可以在调用点打断点,单步调试,看到到底发生了什么。用事件的话,调用方不知道谁在监听。监听方不知道谁在调用。它们之间的连接只存在于运行时的事件订阅列表中,你的调试器看不到。
于是你加了个 Debug.Log:
private void HandleDamage(int amount)
{
Debug.Log($"HandleDamage called with amount={amount}");
// actual logic...
}
一个事件这么做没问题。现在乘以项目里每个事件上的每个监听器。你最后得到每帧 500 行日志在 Console 里刷,刷的速度比你看的快。你尝试按关键词过滤,但三条不同的日志里 "Damage" 拼法不一样。你加时间戳、加调用者名字、加堆栈跟踪。每条 Debug.Log 变成三行格式化代码包着一行实际日志。
发布的时候呢?你要全部删掉。或者用 #if UNITY_EDITOR 包起来。或者留着然后祈祷没人注意到每帧格式化 500 条日志消息带来的性能损失。
Debug.Log 作为调试策略就像水桶作为管道策略。紧急情况下能用,但你不会围绕它来设计房子。
Unity Profiler:用错了工具
Unity 的 Profiler 擅长回答"哪个方法花了多长时间"。它非常不擅长回答"哪个事件触发了、什么时候、带什么数据、谁响应了"。
你在 Profiler 里看到一个尖峰。在某个回调方法里 —— HandleDamage。你往下翻调用栈。它被……事件系统的分发循环调用了。哪个事件?Profiler 不知道。它只看到一个来自通用分发函数的方法调用。哪个监听器慢了?你得逐个做插桩。传了什么数据?Profiler 不捕获参数。
Profiler 告诉你时间花在了哪里。它不告诉你事件系统为什么那样运行。这是本质不同的两个问题。
你的 OnPlayerDamaged 上有 8 个监听器,其中一个花了 4ms。Profiler 显示事件系统分发方法里有个尖峰。好的。8 个监听器里哪个是罪魁祸首?你可以在每个监听器里加 Stopwatch 然后打日志。8 个监听器,1 个事件。你有 60 个事件。那就是 480 行计时代码,而你调试还没开始呢。
依赖关系问题
这个问题让架构师夜不能寐:"谁在用这个事件?"
你想把 OnPlayerDeath 改名为 OnPlayerDefeated,因为设计改了,不再有"死亡"了 —— 玩家被"击倒"。简单的重命名对吧?
你在整个项目里 Ctrl+F:OnPlayerDeath。找到 12 个代码引用。全部改名。发布。
然后你收到 Bug 报告:数据分析系统不再追踪玩家战败了。为什么?因为数据分析的 MonoBehaviour 有一个 Inspector 里的序列化字段引用了旧的 OnPlayerDeath ScriptableObject。Ctrl+F 只能找到代码引用。它找不到 Inspector 绑定。找不到 Behavior Window 订阅。找不到任何存在于序列化 Unity 资产而不是 .cs 文件中的引用。
这就是为什么没人敢删事件。没人敢改名。没人重构事件层级。因为没人知道全貌。"谁在用这个事件?"用标准 Unity 工具是个无法回答的问题。于是事件不断堆积。死事件永远留在项目里。事件数据库不断膨胀。新开发者看着 200 个事件,完全不知道哪些是活跃的。
对重构的恐惧是真实存在的,而且直接源于可观测性的断层。
冻结游戏的递归循环
事件 A 触发 B。B 的监听器触发 C。C 的监听器触发 A。游戏卡死。编辑器无响应。你强制退出 Unity,丢失了未保存的场景修改,然后花 20 分钟盯着代码试图搞清楚循环从哪里开始。
递归事件循环是事件驱动系统里最恶心的 Bug 之一。设计期完全看不出来 —— 只有当三个事件恰好同时活跃且带着正确的监听器时循环才会出现。Code Review 也发现不了,因为没有任何单个文件包含完整的循环。每个脚本只是响应一个事件时触发另一个。单独看完全合理。组合在一起就是灾难。
没有自动检测的话,你只能通过最惨的方式发现 —— 卡死的编辑器和栈溢出。
DevOps 有的东西(我们没有)
后端开发的世界几年前就解决了这个问题。分布式追踪(Jaeger、Zipkin)让你跟踪一个请求穿过 15 个微服务,看到它在每一步花了多长时间。指标面板(Grafana、Datadog)实时显示请求速率、错误率、延迟百分位。日志聚合(ELK 栈、Splunk)让你用结构化查询搜索数百万条日志。告警系统(Prometheus、PagerDuty)在用户投诉之前就通知你。
游戏事件在架构上跟微服务消息很像。事件触发(发送请求),多个监听器响应(多个服务处理),结果向下游传播(触发更多事件)。同样的可观测性技术完全适用。
但 Unity 的工具箱给我们的是……Profiler 和 Debug.Log。我们值得更好的。
GES 的答案:两个互补的工具
GES 用两个专门构建的工具解决可观测性断层,覆盖完整的开发生命周期:Event Finder 用于编辑期的依赖分析,Runtime Monitor 用于运行期的可观测性。合在一起,它们回答了标准 Unity 工具回答不了的每一个问题。
Event Finder:谁在用这个事件?
Event Finder 是一个编辑器窗口,确定性地回答依赖关系问题。选择任何事件资产,点击 Scan,它就能找到场景中每个引用了该事件的 MonoBehaviour —— 通过公有字段、私有序列化字段和嵌套引用。它使用反射扫描组件字段,所以能捕获 Ctrl+F 永远找不到的引用。
列表视图
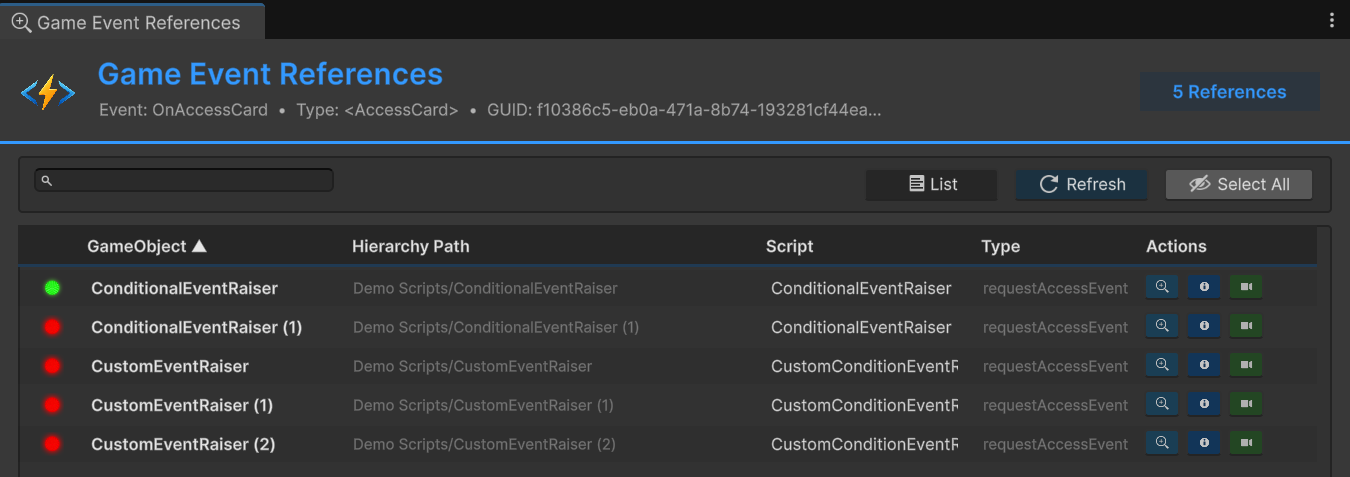
列表视图以平面列表显示所有引用。每条记录显示 GameObject 名称、组件类型、字段名和状态指示器:
- 绿色 —— 引用有效且组件处于活跃状态
- 红色 —— 引用已断开(null 事件、缺失组件或禁用对象)
点击任何条目可以 Ping 它在 Hierarchy 中(高亮但不选中)、Focus 它(选中并在 Scene View 中框选)、或 Frame 它(移动 Scene 摄像机以居中显示对象)。
分组视图
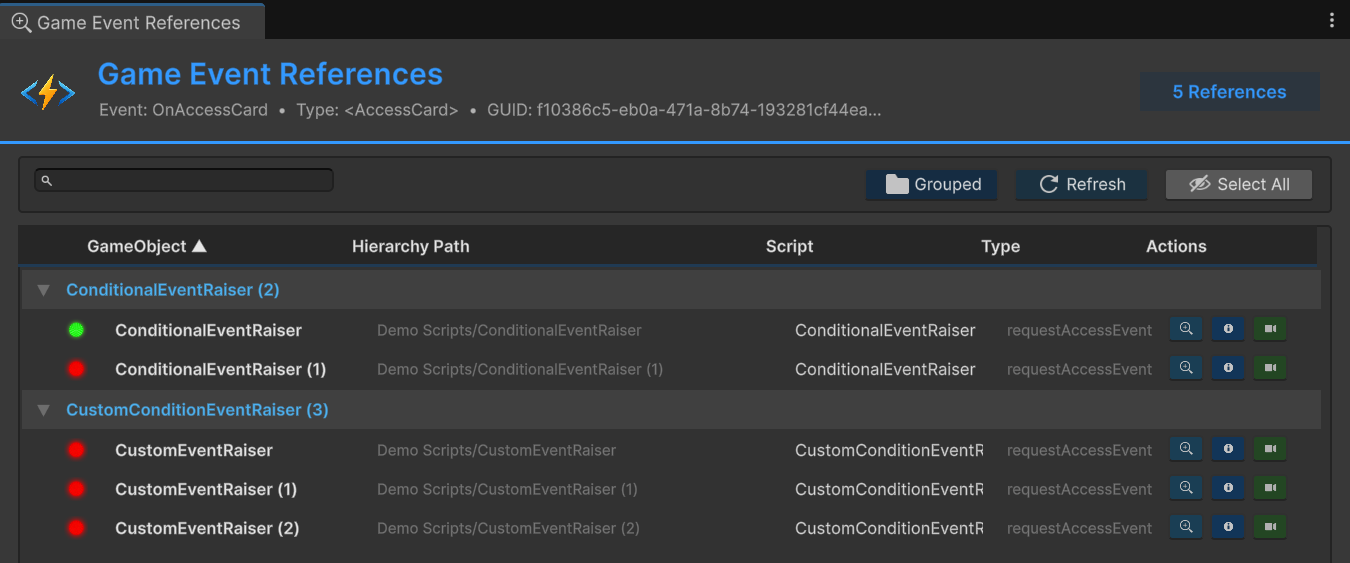
分组视图按组件类型组织引用。所有 HealthSystem 引用放一起,所有 DamagePopup 引用放一起。当你要回答"哪些系统用了这个事件"而不是"哪些对象引用了它"时,用这个视图。
安全重构工作流
Event Finder 让"谁在用这个事件?"从无法回答变成 30 秒的查询:
- 打开 Event Finder,选择你要改名/删除/修改的事件
- 点击 Scan —— 获得完整的引用列表
- 在列表视图中审查每个引用(检查意外的消费者)
- 切换到分组视图了解哪些系统受影响
- 自信地做出修改
- 重新扫描验证没有东西坏掉(全部绿色状态)
不用猜。不用"我觉得我们都覆盖到了"。不用两周后因为漏了个 Inspector 绑定而收到 Bug 报告。Event Finder 通过让依赖可见来让重构变得安全。
Runtime Monitor:专为事件打造的可观测性
Runtime Monitor 是一个带 8 个专门标签页的编辑器窗口,每个都设计来回答一类特定的调试问题。它原生理解事件、监听器、条件、时序和流程图 —— 因为它内置在事件系统中,不是事后硬接上去的。
通过 Tools > TinyGiants > Game Event System > Runtime Monitor 打开,或在 GES Hub 中找到。Monitor 在 Play Mode 期间以极低开销收集数据。它是纯编辑器代码,构建时完全剥离。对你发布的游戏零影响。
让我们逐一看看全部八个标签页。
标签页 1:Dashboard —— 健康检查
Dashboard 是你的起点。看一眼就知道你的事件系统是健康的还是着火了。
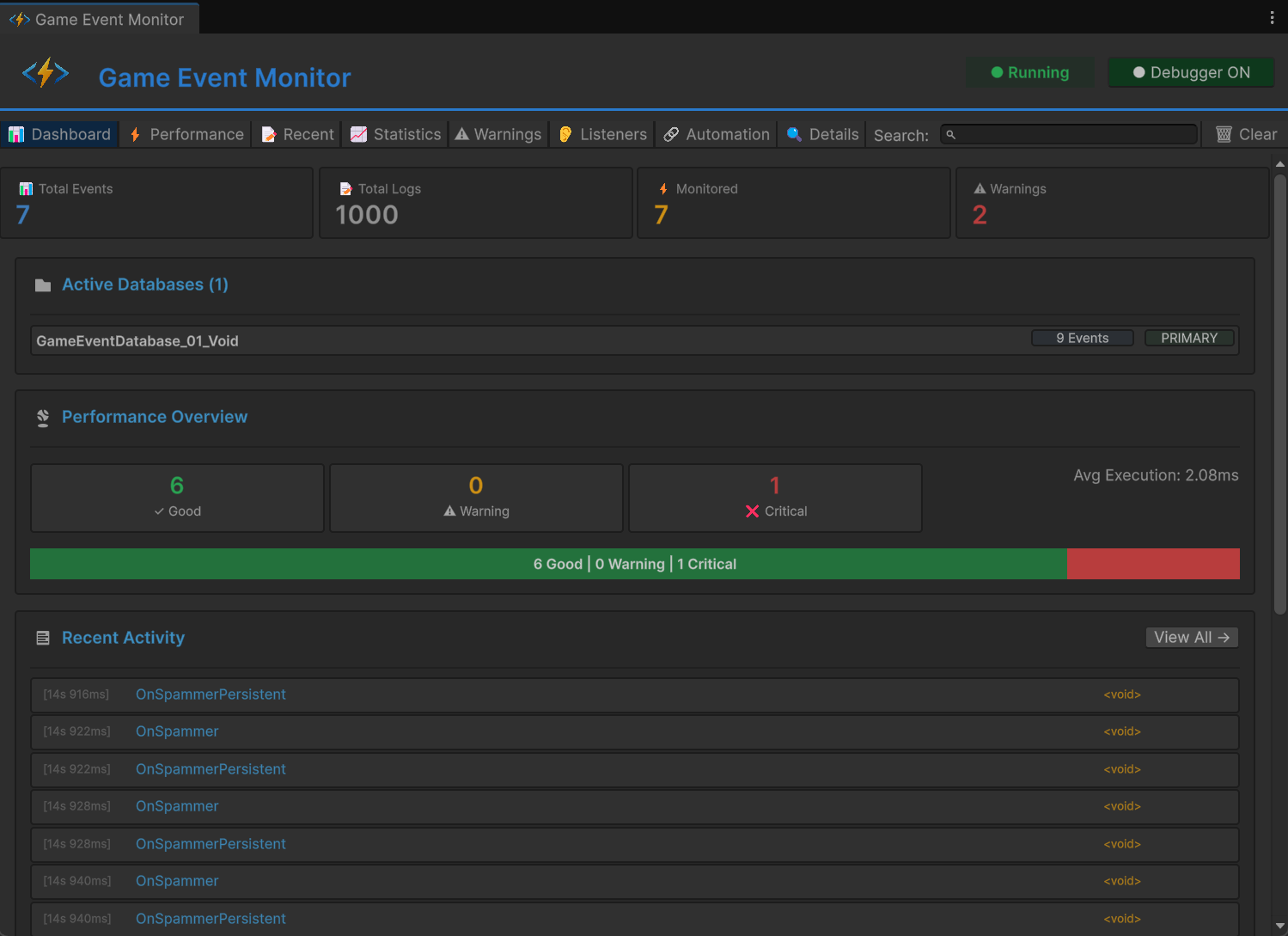
顶部的指标卡片展示大局:项目中的事件总数、本次会话的活跃事件(至少触发过一次)、监听器订阅总数、和 Play Mode 启动以来的累计触发次数。
性能条带颜色编码。绿色表示所有事件的平均处理时间低于 1ms —— 没问题。黄色表示部分事件平均 1-10ms —— 值得看看。红色表示有东西超过 10ms —— 停下来调查。这个条反映的是表现最差的事件,不是平均值。一颗老鼠屎就能把整条变黄。这是故意的 —— 你需要知道异常值。
最近活动实时滚动显示最近几次事件触发:事件名、时间戳、监听器数量、执行时间。游戏过程中,这给你一个事件系统正在做什么的实时脉搏。
快速警告汇总检测到的问题:高执行时间、高监听器数量、递归触发、内存分配。点击警告徽章跳转到相关的详情标签页。
Dashboard 回答的是:"我的事件系统现在健康吗?"如果是,继续干活。如果不是,其他标签页告诉你为什么。
标签页 2:Performance —— 硬数据
当你感觉到某些东西变慢了、需要数据而不是感觉的时候来这里。
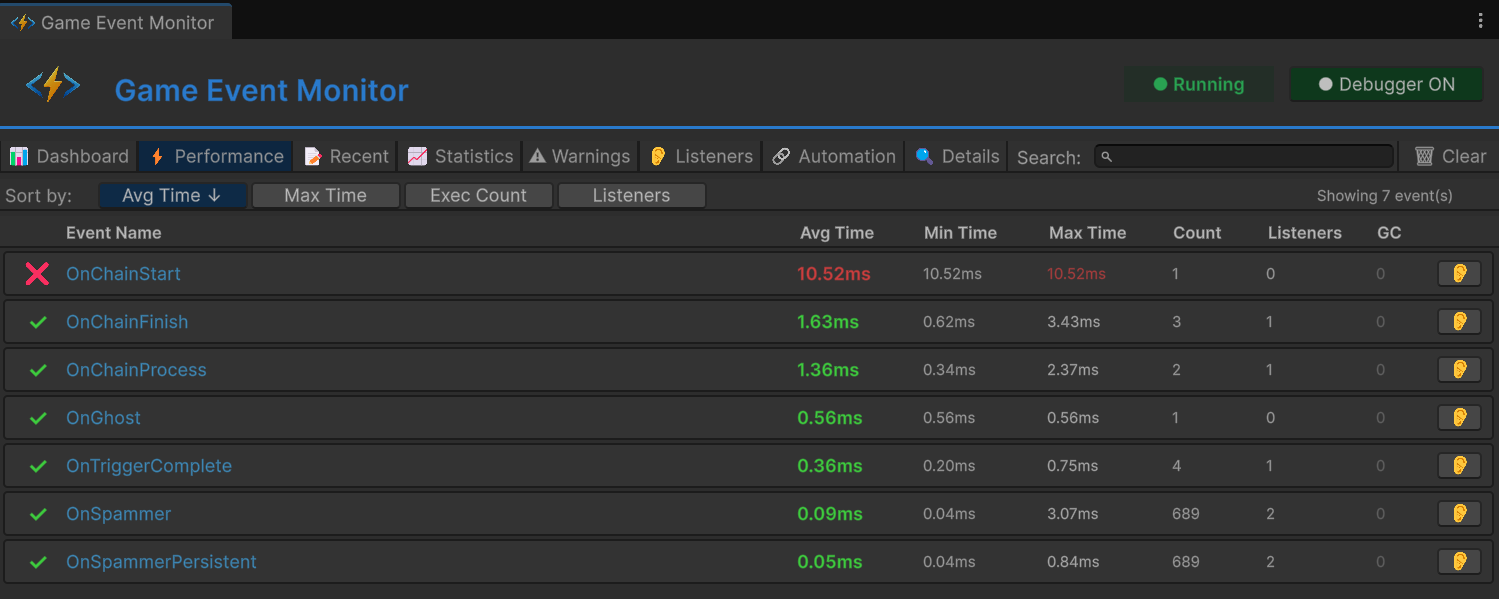
项目里的每个事件都有一行:
- Event Name —— ScriptableObject 资产名
- Raise Count —— 本次会话触发了多少次
- Listener Count —— 当前活跃订阅者数量
- Avg/Min/Max Time —— 每次触发的执行时间,跨所有监听器
- GC Alloc —— 每次触发的垃圾回收分配
时间单元格带颜色编码:绿色(<1ms)正常,黄色(1-10ms)偏高,红色(>10ms)严重。按任意列排序 —— 按 "Max Time" 排序找到尖峰罪魁祸首,按 "GC Alloc" 排序找到分配热点,按 "Raise Count" 排序找到高频事件。
让 Performance 标签页强大的洞察是:事件执行时间包含所有监听器的工作。 如果一个事件平均 5ms、有 50 个监听器,那就是每个监听器约 0.1ms —— 正常。如果平均 5ms 只有 2 个监听器,那其中一个在做昂贵的操作。数字立刻告诉你问题是"监听器太多"还是"某个监听器太慢"。
标签页 3:Recent Events —— 时间线
按时间顺序记录的每次事件触发。这是你的事件系统黑匣子。
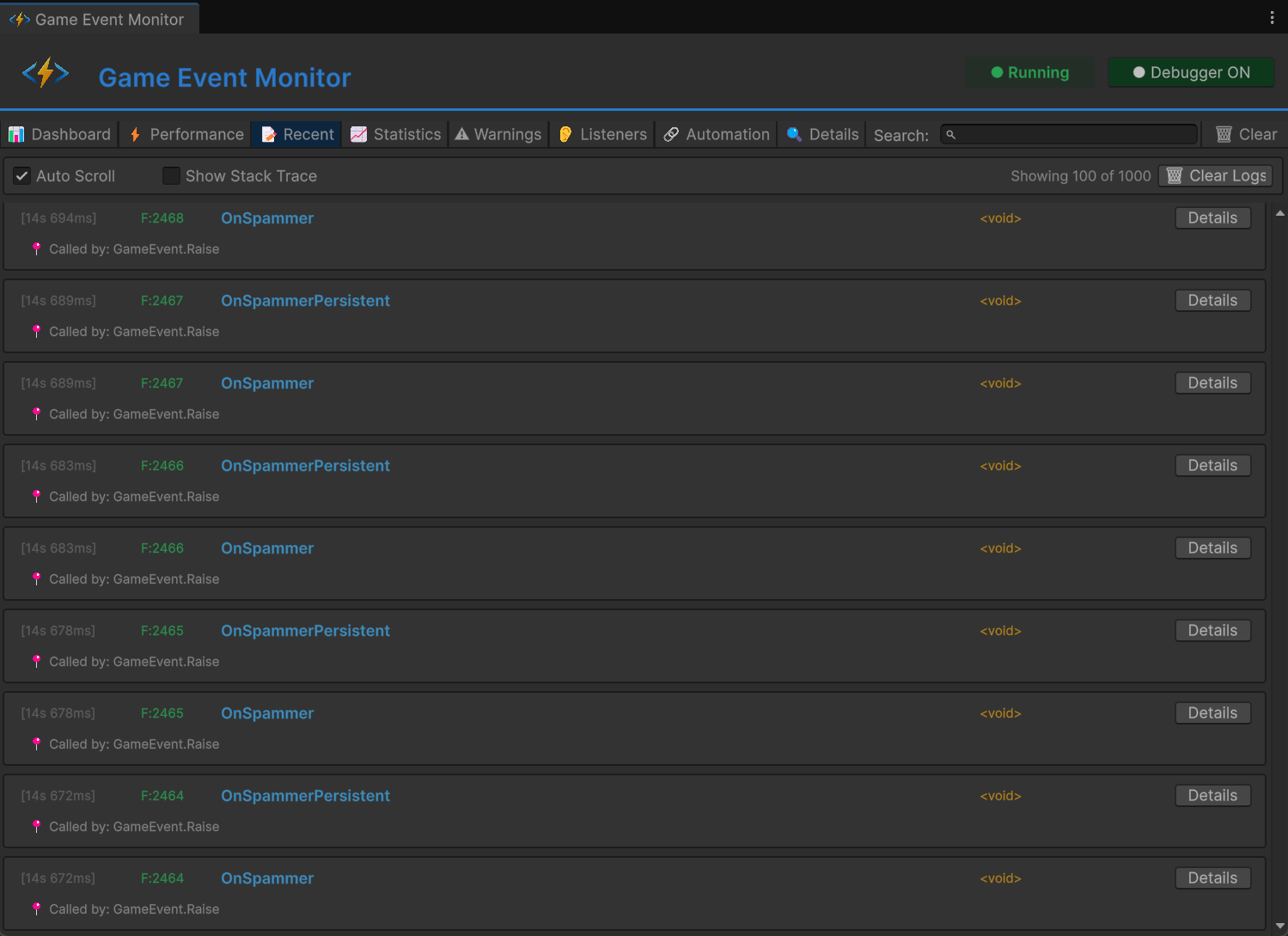
每条记录显示:时间戳(游戏时间)、事件名、参数值(字符串显示)、调用 Raise() 的脚本和方法、触发时的监听器数量、和执行时间。
点击任何条目查看完整调用栈。这对于回答"谁触发了这个?"非常有价值 —— 特别是当多个系统可以触发同一个事件时:
PlayerCombat.TakeDamage() at PlayerCombat.cs:47
-> Int32GameEvent.Raise(42)
现在你知道伤害事件来自 PlayerCombat 系统的第 47 行,参数是 42。
按事件名过滤来实时观察特定事件。设置为 OnKeyPickedUp 然后走一遍捡钥匙的流程。有吗?什么时候触发的?什么参数?如果没有,问题在上游 —— 触发方没调用 Raise()。如果有且数据正确,问题在下游 —— 查 Listeners 标签页。
按时间范围过滤(最近 N 秒)或按最小执行时间过滤(只显示尖峰)。
Recent 标签页把"这个事件到底触发了没"从猜测变成了查询。
标签页 4:Statistics —— 模式发现
Recent 显示个别事件,Statistics 显示一段时间内的聚合行为。
频率分析: 每秒事件总数(实时)、单事件频率(每秒和每分钟的触发次数)、和分布直方图。
使用模式: 最活跃的事件(按总触发次数排序)、最不活跃的事件(触发零次 —— 可能是死代码)、最繁忙的时刻(峰值活动的时间段)、和监听器增长趋势。
这个标签页能揭示你逐一检查永远发现不了的东西。比如发现 OnPositionUpdated —— 你以为是个"偶尔"触发的事件 —— 实际上每秒触发 60 次、有 20 个监听器。那就是每秒 1200 次监听器执行。即使每次 0.01ms,那也是每秒 12ms 的 CPU 时间,就一个事件。在移动端,这很重要。
或者发现 OnBossDied 在包含 Boss 战的完整通关后触发次数为零。要么事件没连对,要么是死代码。无论哪种你都需要知道。
标签页 5:Warnings —— 自动健康检查
Warnings 标签页监视你的事件系统并自动标记问题。你不需要知道该找什么 —— 它知道。
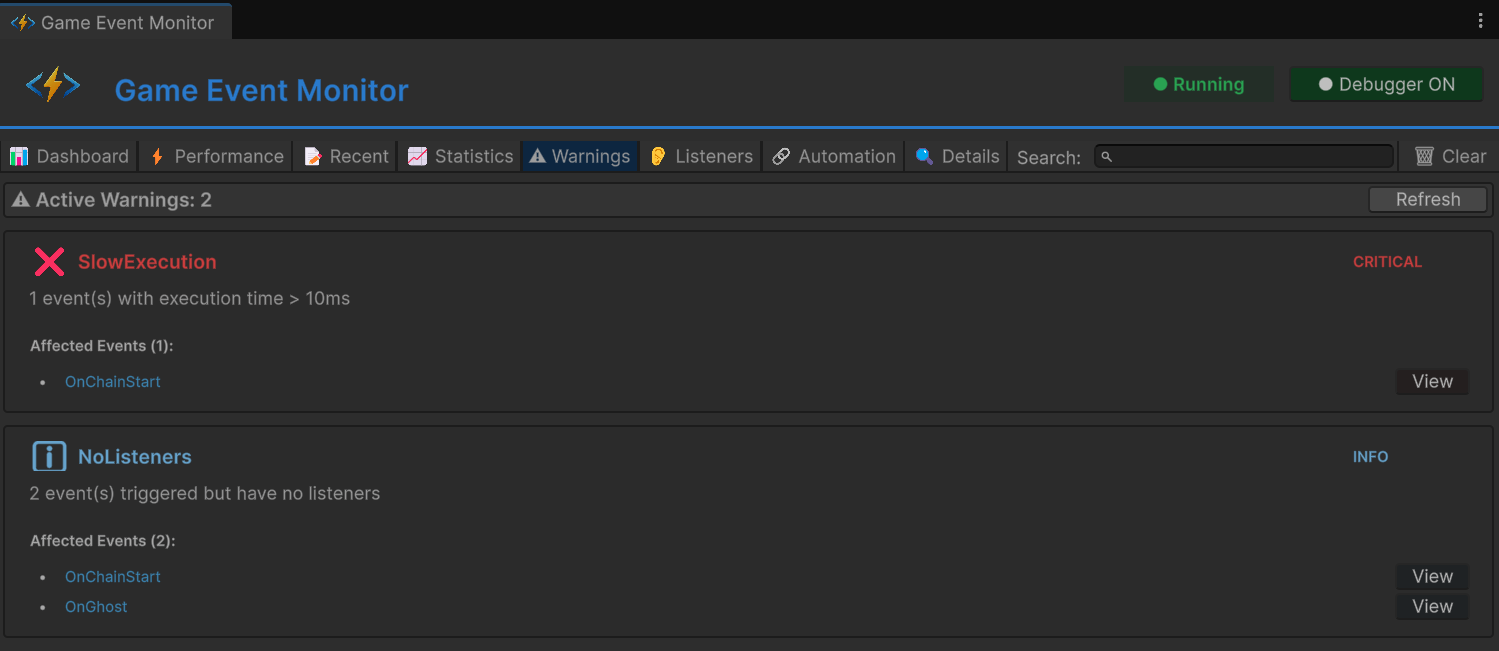
性能警告:
- 事件执行时间 > 10ms(红色)
- 事件执行时间 > 5ms(黄色)
- 事件每秒触发 > 100 次且没有 Conditional Listener(黄色)
监听器警告:
- 事件监听器 > 50 个(黄色)
- 事件监听器 > 100 个(红色)
- 非 DontDestroyOnLoad 对象上的 Persistent Listener(黄色)
内存警告:
- 事件触发导致 GC 分配(黄色)
- 高频事件伴随 GC 分配(红色)
递归警告:
- 事件在已经处理中时被再次触发(红色)
- 检测到环形 Trigger/Chain 依赖(红色)
每条警告包含事件名、触发它的具体指标、和建议操作。不只是说"这有问题",而是"考虑添加 Conditional Listener 来减少执行次数"或"检查是否缺少 RemoveListener 调用"。
光是递归检测就值回票价。事件 A 触发 B 触发 A 触发 B…… 是事件驱动系统里最恶心的 Bug 之一。没有自动检测的话,你只能在游戏冻结和栈溢出时才发现。Warnings 标签页在它发生的瞬间就捕获了,并告诉你确切涉及哪些事件。
标签页 6:Listeners —— 订阅地图
这个标签页显示每个活跃的监听器订阅,按事件和监听器类型组织。
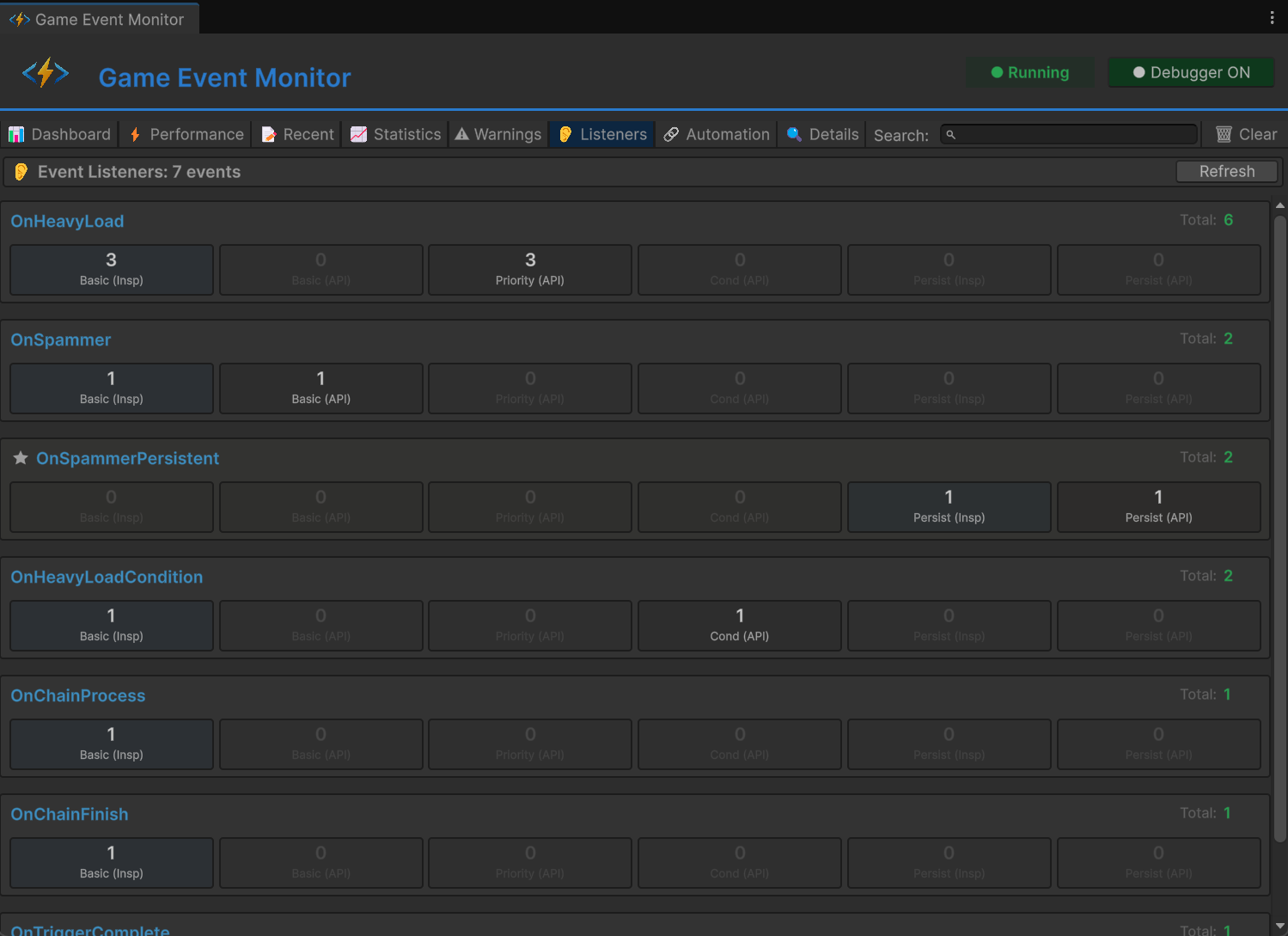
展开任何事件查看按层分组的监听器:
OnPlayerDamaged (12 listeners)
+-- Basic (4)
| +-- HealthSystem.HandleDamage
| +-- HitFlash.ShowFlash
| +-- CameraShake.OnDamage
| +-- SoundManager.PlayHitSound
+-- Priority (3)
| +-- [200] ArmorSystem.ReduceDamage
| +-- [100] HealthSystem.ApplyDamage
| +-- [25] HealthUI.RefreshBar
+-- Conditional (2)
| +-- [cond] BossModifier.ApplyBossMultiplier
| +-- [cond] CriticalHit.CheckCritical
+-- Persistent (1)
| +-- AnalyticsManager.TrackDamage
+-- Triggers (1)
| +-- -> OnScreenShake (delay: 0s)
+-- Chains (1)
+-- -> OnDamageNumber (delay: 0.1s, duration: 0.5s)
订阅审计: 验证预期的监听器确实订阅了。"为什么受击音效没播放?"看这里 —— SoundManager.PlayHitSound 在列表里吗?如果不在,订阅就缺失了(可能是生命周期问题 —— 对象被销毁又重建但没重新订阅)。
优先级验证: 确认执行顺序合理。如果 UI 更新(优先级 25)在数据变更(优先级 100)之前处理,你的优先级值搞反了。
泄漏检测: 如果一个本应已被销毁的对象的监听器还出现在这里,你就找到了一个订阅泄漏。监听器的目标是过期的,你缺少了 OnDisable 或 OnDestroy 中的 RemoveListener 调用。
标签页 7:Automation —— 流程地图
这个标签页将事件到事件的连接 —— Trigger 和 Chain —— 可视化为依赖图。
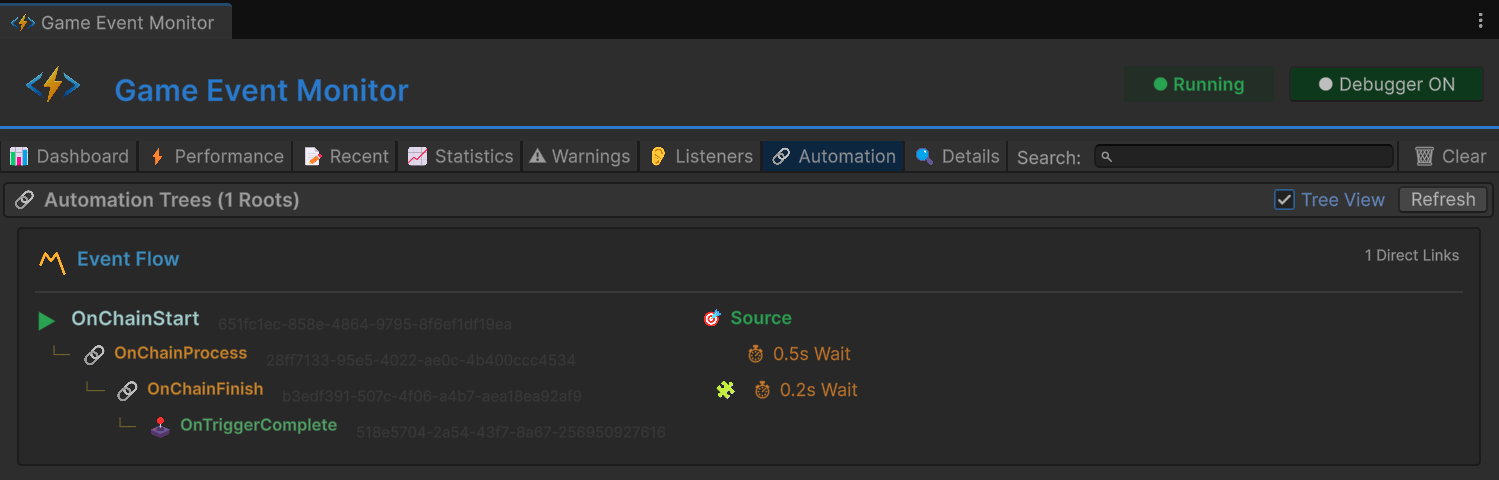
树形视图把每个事件作为根节点,传出连接作为子节点:
OnBossDefeated
+-- [trigger] -> OnPlayVictoryMusic (delay: 0s)
+-- [trigger] -> OnShowVictoryUI (delay: 1s)
+-- [chain] -> OnSaveProgress (delay: 2s)
+-- [chain] -> OnLoadNextLevel (delay: 0.5s)
非常适合回答"Boss 死了之后还发生了什么?"沿着树看下去就能看到完整的传播路径。
两个视图都显示在 Node Editor 中可视化配置的连接(标记"visual")和运行时程序化创建的连接(标记"runtime")。如果一个流程不工作,检查预期的连接是否存在。如果显示"visual"但没有"runtime",配置是对的但有什么阻止了运行时初始化。
标签页 8:Details —— 深入分析
在任何其他标签页中点击任何事件,Details 标签页就会打开该事件的全面视图。
总触发次数、平均/最小/最大执行时间、按类型划分的当前监听器数量、每次触发的 GC 分配、最近 60 秒的频率、最后一次触发的时间戳和参数。一眼了解一个事件的全部行为所需的一切。
关键的附加功能:逐监听器分解。 Performance 标签页显示每个事件的聚合时间,Details 标签页显示单个事件内每个监听器的时间。
如果 OnPlayerDamaged 平均 3ms、有 10 个监听器,Details 标签页会告诉你 ArmorSystem.ReduceDamage 花了 2.5ms,其他 9 个各花 0.05ms。现在你确切知道该优化哪里。不用猜,不用给每个 Handler 加 Stopwatch 插桩,不用 Debug.Log 计时代码。
监听器历史部分显示一段时间内的添加和移除:
[0.0s] + AddListener: HealthSystem.HandleDamage
[0.0s] + AddPriorityListener: ArmorSystem.ReduceDamage (200)
[15.3s] - RemoveListener: HealthSystem.HandleDamage
[15.3s] + AddListener: HealthSystem.HandleDamage
[45.0s] + AddConditionalListener: BossModifier.Apply (100)
这帮助调试"幽灵监听器"问题 —— 因对象生命周期事件(场景加载、对象池、启用/禁用循环)而出现和消失的监听器。
完整的调试工作流
让我重新审视开头的门 Bug。有了这两个工具,调查过程是这样的:
第 1 步:复现。 存档/读档后捡钥匙。门没开。
第 2 步:查看 Recent Events。 打开 Runtime Monitor 的 Recent 标签页,按 OnKeyPickedUp 过滤。有吗?有 —— 在时间戳 23.4 秒触发,钥匙 ID 正确。触发没问题。问题在下游。
第 3 步:查看 Listeners。 切换到 Listeners 标签页,找 OnKeyPickedUp。门的监听器订阅了吗?没有 —— 缺失。存档/读档之前是有的,但现在没了。
第 4 步:定位根因。 门的监听器在 OnEnable 中注册。加载后,门对象被销毁并重新创建,但 OnEnable 在事件数据库加载完成之前就运行了。监听器试图订阅一个 null 事件引用。
第 5 步:验证修复。 修复初始化顺序后,用 Event Finder 扫描 OnKeyPickedUp,确认门的引用是绿色(有效)。再次走一遍存档/读档流程。查看 Recent Events —— 事件触发了。查看 Listeners —— 门已订阅。门开了。Bug 修复。
总调查时间: 大约 90 秒。没有 Debug.Log。没有猜测。没有"在我机器上没问题"。
编辑期 + 运行期 = 全覆盖
Event Finder 和 Runtime Monitor 完美互补,因为它们覆盖了开发的不同阶段:
| 工具 | 阶段 | 它回答的问题 |
|---|---|---|
| Event Finder | 编辑期 | "谁引用了这个事件?""改名/删除安全吗?""所有绑定都有效吗?" |
| Monitor Dashboard | 运行期 | "我的事件系统现在健康吗?" |
| Monitor Performance | 运行期 | "哪些事件慢了,为什么?" |
| Monitor Recent | 运行期 | "刚才发生了什么,什么顺序?" |
| Monitor Statistics | 运行期 | "长期的使用模式是什么?" |
| Monitor Warnings | 运行期 | "我该担心什么?" |
| Monitor Listeners | 运行期 | "谁在监听什么,现在?" |
| Monitor Automation | 运行期 | "事件之间是怎么连接的?" |
| Monitor Details | 运行期 | "告诉我这个事件的一切。" |
Event Finder 给你重构的信心。Runtime Monitor 给你运行中游戏行为正确的信心。合在一起,它们弥合了让事件驱动架构调试起来如此痛苦的可观测性断层。
事件驱动架构很强大。但强大却没有可见性,只不过是用更花哨的方式制造你找不到的 Bug。这些工具给你可见性。开发时保持 Dashboard 打开。重构前跑一遍 Event Finder。当有什么感觉不对时,你会知道该查哪个标签页 —— 答案已经在那里等你了,而不是埋在 500 行 Debug.Log 输出里。
🚀 全球开发者服务矩阵
🇨🇳 国区开发者社区
- 🛒 Unity 中国资产商店
- 🎥 B站官方视频教程
- 📘 高性能架构技术文档
- 💬 国内技术交流群 (1071507578)
🌐 全球开发者社区
📧 支持与合作
- 🌐 TinyGiants 工作室主页
- ✉️ 官方支持邮箱